
Introduction
Microprocessor and system thermal management are linked to facility cooling: power dissipation and cooling techniques employed at one end of the size scale have cascading impacts at the other extreme (Figure 1). For example, ineffective airflow distribution or insufficient underfloor static pressure in a data center can reduce the supply airflow rate from cold-aisle floor tiles, adversely impacting inlet air temperatures and causing microprocessor thermal and reliability problems [1, 2]. Conversely, on the component level, the continued growth in microprocessor power dissipation, and the attendant increase in equipment heat load and cooling airflow requirements, creates challenges for facility air conditioning design, deployment, and operation [3, 4].
 |
Figure 1. The heat transfer path at changing length scales.In addition to the existing literature on electronics cooling, there is increased attention being paid to the modeling, prediction, and control of room-level and facility-wide temperature distributions [5, 6]. This includes recent work addressing the impact of locally-elevated equipment power densities on the temperature of surrounding areas [7, 8]. Yet even as equipment performance and power efficiency continue to rise (measured as operations per unit of energy), the growing demand for compute density continues to outpace the efficiency gains (Figure 2). There has been a response at the microprocessor, component, and room levels to these trends (e.g., reduced power and improved airflow distribution), yet to date little focus on specific server architecture changes.
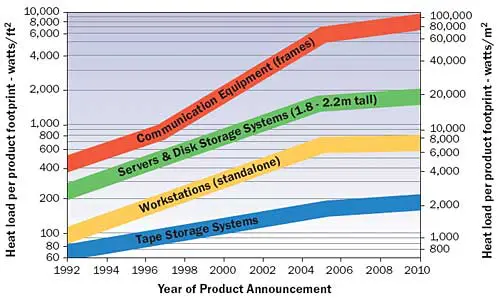 |
Figure 2. Product heat density trend chart [4] (The Uptime Institute).
System Power vs. Airflow
The system-level airflow required to achieve a desired junction-to-ambient thermal resistance (![]() ja) often is at odds with the ability of computer room air-conditioners (CRACs) to supply chilled air from perforated floor tiles. A reduction in
ja) often is at odds with the ability of computer room air-conditioners (CRACs) to supply chilled air from perforated floor tiles. A reduction in ![]() ja is a necessity, given increased microprocessor power dissipation and thermal non-uniformity. In order to reduce
ja is a necessity, given increased microprocessor power dissipation and thermal non-uniformity. In order to reduce ![]() ja for a particular heatsink design, the ratio of airflow to power dissipation must increase, leading to a lower
ja for a particular heatsink design, the ratio of airflow to power dissipation must increase, leading to a lower ![]() T between system inlet and exhaust. However, as the temperature difference between cold-aisle and hot-aisle goes down, the effective cooling capacity per floor tile decreases (Figure 3). Thus, component thermal management can confound facility cooling capability. This does not address the serious challenges in maintaining sufficient underfloor static pressure to achieve favorable room-level airflow distribution.
T between system inlet and exhaust. However, as the temperature difference between cold-aisle and hot-aisle goes down, the effective cooling capacity per floor tile decreases (Figure 3). Thus, component thermal management can confound facility cooling capability. This does not address the serious challenges in maintaining sufficient underfloor static pressure to achieve favorable room-level airflow distribution.
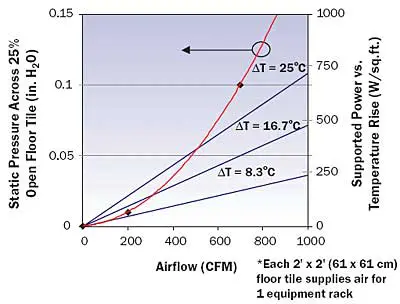 |
Figure 3. Airflow vs. static pressure and thermal capacity vs. hot-aisle/cold-aisle ![]() T for 25% open floor tile.Thus, the imbalance between rack-level air consumption and floor supply volume in a typical raised floor environment results in recirculation between hot-aisle and cold-aisle, where upper systems in a rack draw heated and mixed exhaust air, causing an increase in peak inlet temperatures [9, 10, 11]. A similar analysis holds for other air supply schemes. In the example shown in Figure 4, equipment airflow consumption that exceeds the volume delivered from a floor tile produces an additional 18° F (10° C) rise in inlet air temperature over ambient. This example illustrates the benefits of matching equipment aggregate air consumption to expected floor supply volumes. For the same reason, server closed-loop fan speed control is also highly desirable. In summary, system designs that work well in isolation – either on a test stand, in the wind tunnel, or in a computer simulation – may not be good residents in large facility aggregations.
T for 25% open floor tile.Thus, the imbalance between rack-level air consumption and floor supply volume in a typical raised floor environment results in recirculation between hot-aisle and cold-aisle, where upper systems in a rack draw heated and mixed exhaust air, causing an increase in peak inlet temperatures [9, 10, 11]. A similar analysis holds for other air supply schemes. In the example shown in Figure 4, equipment airflow consumption that exceeds the volume delivered from a floor tile produces an additional 18° F (10° C) rise in inlet air temperature over ambient. This example illustrates the benefits of matching equipment aggregate air consumption to expected floor supply volumes. For the same reason, server closed-loop fan speed control is also highly desirable. In summary, system designs that work well in isolation – either on a test stand, in the wind tunnel, or in a computer simulation – may not be good residents in large facility aggregations.
 |
Figure 4. Elevated inlet temperatures die to airflow recirculation.
High-Performance/High-Impedance Heatsinks
Reducing airflow and increasing the temperature rise through the system to improve data center thermal density requires heatsinks to deliver an aggressive ![]() ja at lower flow rates (i.e., heatsinks with greater flow impedance.) Also driving this requirement are the shrinking form factors available for heatsinks in ultra-dense server systems. For example, a low-profile aluminum heatsink for a 130 W-class microprocessor in a concept 1U chassis can sink the same thermal load as a “tall” baseline copper heatsink design at a similar flowrate, although at nearly four times the flow impedance (0.375″ H2O vs. ~0.1″ H2O [94 Pa vs. ~25 Pa]) [12]. At reduced airflow, the same consequences due to increased
ja at lower flow rates (i.e., heatsinks with greater flow impedance.) Also driving this requirement are the shrinking form factors available for heatsinks in ultra-dense server systems. For example, a low-profile aluminum heatsink for a 130 W-class microprocessor in a concept 1U chassis can sink the same thermal load as a “tall” baseline copper heatsink design at a similar flowrate, although at nearly four times the flow impedance (0.375″ H2O vs. ~0.1″ H2O [94 Pa vs. ~25 Pa]) [12]. At reduced airflow, the same consequences due to increased ![]() ja hold for all heatsink designs, whether traditional extruded, brazed, or bonded fin heatsinks, or for advanced forming methods such as crimped, skived, micro-forged, or machined fin structures – and even with the addition of phase-change chambers to improve lateral spreading above the microprocessor die.A final consideration is lowering the heatsink inlet temperature by reducing in-system mixing and preheat from other powered devices in the upstream flow path (e.g., power supplies, chipset components, etc.) Ducting or drawing air directly from the front of the chassis can yield 5 – 20°C relief to the microprocessor thermal design (Figure 5) [13].
ja hold for all heatsink designs, whether traditional extruded, brazed, or bonded fin heatsinks, or for advanced forming methods such as crimped, skived, micro-forged, or machined fin structures – and even with the addition of phase-change chambers to improve lateral spreading above the microprocessor die.A final consideration is lowering the heatsink inlet temperature by reducing in-system mixing and preheat from other powered devices in the upstream flow path (e.g., power supplies, chipset components, etc.) Ducting or drawing air directly from the front of the chassis can yield 5 – 20°C relief to the microprocessor thermal design (Figure 5) [13].
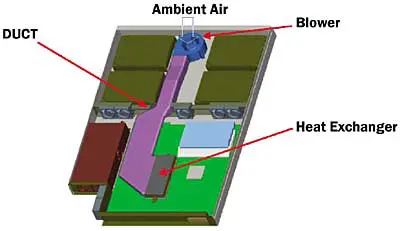 |
Figure 5. Fresh-air ducting to microprocessor heatsinks [13].
Airmover Selection and Design
Airmover selection and design for new high-power systems will need to take into account several related trends, including: reduced form factors, increased flow impedance, reduced acoustic signature and electronic emissions, and improved reliability. Consider first the implications of smaller system sizes and higher static pressures.
Current strategies in 1U system cooling rely either on numerous commercial off-the-shelf axial fans, on small ducted radial impellers, or on a combination of the two. As the shortest dimension in the chassis sets the constraint on axial fan diameter, a 1U system can only fit a 40 mm axial fan. However, an analysis of expected system pressure drop characteristics when utilizing high-impedance heatsinks indicates that 40 mm fans are not a good match for this cooling scenario. A high-powered server cooling solution could require as many as 12 fans throughout the system – and this still may not achieve cooling system redundancy [14].
In contrast, ducted impellers allow larger wheel diameters, higher shutoff pressures, lower rotational velocities, and potentially greater flow rates. Therefore, it is possible to consider a cooling strategy that combines axial fans and radial blowers to achieve the necessary flow, pressure, and airflow distribution characteristics. However, there are concerns with an approach that utilizes multiple non-redundant fans, as an increase in the number of potential failure candidates can drastically reduce system reliability.
Thus, for the densest 1U system architectures, a single radial impeller drawing air from the front of the chassis may represent the optimal solution. Given current hard drive packaging and form factor advances, this still leaves room for up to 500 GBytes of conventionally-sized storage or up to six compact-format hard drives, permitting true RAID-5 (Redundant Array of Independent Disks) storage operation. In short, reliable radial blowers offer a compelling option in compressed server chassis.
Cooling System Reliability
When a server’s cooling subsystem is a major contributor to overall system reliability, high availability is typically achieved by redundancy of failure-prone components within the system (i.e., no single points of failure) or redundancy provided at the system level. For rack-mount servers with form factors of 4U or greater, cooling subsystem reliability typically is achieved by fans that are redundant (to eliminate single points of failure). These fans typically are hot-swappable (to improve maintainability) with failure alerting complemented with failure prediction through server management software.
However as airflow and static pressure requirements go up in dense 1U and 2U form factor servers, it becomes increasingly difficult to provide a reliable cooling subsystem under all possible environmental conditions by employing component level redundancy. For multi-fan systems, achieving high reliability for the cooling subsystem is only practicable with redundant designs; the alternative being that each fan must be made “hyper-reliable” to mitigate the consequences of failure of any one device.
An alternate approach is to employ a single, non-redundant fan, with the bearings and control electronics selected to achieve the required level of reliability. A moderate reliability target for a single airmover may be a cost and maintenance prohibitive option with multiple non-redundant fans.
The inclusion of server management features such as failure detection or prediction logic into the fan control electronics raises additional issues. Proper implementation of failure detection allows individual component reliability to be reduced because maintainability is improved – a failed component is detected, isolated, the user is alerted, and repair scheduled almost instantaneously. Thus, the overall system availability still can remain at an enterprise level. This solution is not without tradeoffs. Consider the maintenance implications of multiple redundant fans. With enterprise hardware costs representing a minority of total information technology (IT) expenditures – the greatest single contributor is trained support staff [15] – reducing service costs must be viewed as a high priority. This would seem to argue for a cooling subsystem that minimizes user maintenance requirements.
In short, evaluation of the availability metric needs to be weighted by the cost of service and the time between required maintenance calls. If a maintenance call is required for any predicted or detected hardware failure, then systems with multiple redundant fans will have greater service needs, and consequently higher total costs of ownership, than systems with a single non-redundant fan. Understanding the usage model allows a designer to optimize high-availability and cost in server designs.
This argument is more persuasive when extended beyond the system to an enterprise-critical equipment rack or cluster composed of many servers. With sophisticated networking, failover, load balancing, multi-pathing, data replication and mirroring, RAID technology, and clustering techniques bringing workload redundancy outside the server to the rack-level and beyond, a single node going off-line will not cause a break in service. Furthermore, a graceful system halt (or workload failover) is a critical default requirement when a shutdown is necessary for fan replacement in 1U/2U chassis. Finally, the same mechanism that alerts to a failed fan condition is often used for forecasting, so that an outage can be predicted and dealt with on a scheduled basis. The preceding analysis certainly seems to support the viability of solutions targeted at the high-reliability, logically redundant, low maintenance market segment.
Conclusions
Computer equipment performance and power density continue to grow. While it is possible to air-cool computer equipment with power densities of up to 700 W/U using conventional technology, these methods break down for large aggregations of equipment. Therefore, aligning system power density and facility thermal capacity is critical to future IT expansion. Specific server architecture design elements and conclusions include:
- The imbalance between airflow supply and system cumulative air consumption is a fundamental obstacle to successful thermal management, and a contributor to upper servers in an equipment rack (for a raised-floor facility) experiencing elevated inlet temperatures.
- Extending the limits of air cooling in data centers and other facilities will require greater temperature rise between system inlet and exhaust, potentially leading to heatsink designs with greater fin density and flow impedance.
- The trends toward 1U system form factors and increased system impedance will make a compelling case for a single high-reliability ducted radial blower in systems with high power dissipation levels.
- A departure from low-reliability redundant cooling components to a simpler single high-reliability cooling component is a better approach to reducing total data center cost while insuring availability at the rack-level and beyond.
References
- Turner, W.P. and Koplin, E.C., “Changing Cooling Requirements Leave Many Data Centers at Risk,” The Uptime Institute white paper, 2000.
- Kang, S., Schmidt, R.R., Kelkar, K.M., Radmehr, A., and Patankar, S.V., “A Methodology for the Design of Perforated Tiles in Raised Floor Data Centers Using Computational Flow Analysis,” IEEE Transactions on Components and Packaging Technologies, Vol. 24, No. 2, 2001, pp. 177-83.
- Belady, C., “Cooling and Power Considerations for Semiconductors into the Next Century,” Proceedings of ISLPED ’01, 2001, pp. 100-105.
- “Heat-Density Trends in Data Processing, Computer Systems, and Telecommunications Equipment,” The Uptime Institute white paper, 2000.
- Schmidt, R.R. and Shaukatullah, H., “Computer and Telecommunications Equipment Room Cooling: A Review of the Literature,” IEEE Transactions on Components and Packaging Technologies, Vol. 26, No. 1, 2003, pp. 89-98.
- Patel, C., Bash, C., Belady, C., Stahl, L., and Sullivan, D., “Computational Fluid Dynamics Modeling of High Compute Density Data Centers to Assure System Inlet Air Specifications,” Proceedings of IPACK ’01, Vol. 2, 2001, pp. 821-829.
- Patel, C., Sharma, R., Bash, C., and Beitelmal, A., “Thermal Considerations in Cooling Large Scale High Compute Density Data Centers,” Proceedings of ITHERM ’02, 2002, pp. 767-776.
- Schmidt, R.R., “Hot Spots in Data Centers,” ElectronicsCooling, Vol. 9, No. 3, 2003, pp. 16-22.
- Sullivan, R.F., “Alternating Cold and Hot Aisles Provides More Reliable Cooling for Server Farms,” The Uptime Institute white paper, 2000.
- Schmidt, R.R., “Effect of Data Center Characteristics on Data Processing Equipment Inlet Temperatures,” Proceedings of IPACK ’01, Vol. 2, 2001, pp. 1097-1106.
- Schmidt, R.R. and Cruz, E., “Raised Floor Computer Data Center: Effect on Rack Inlet Temperatures of Chilled Air Exiting both the Hot and Cold Aisles,” Proceedings of ITHERM ’02 , 2002, pp. 580-594.
- De Lorenzo, D.S., “Thermal Design of a High-Density Server,” IEEE Transactions on Components and Packaging Technologies, Vol. 25, No. 4, 2002, pp. 635-640.
- Langley, T.C., Summers, M.D., and Leija, J., “System and Thermal Solutions for 1U Dual Pentium III Processor Design,” Intel Developer Forum, San Jose, CA, February 26 – March 1, 2001.
- Aldridge, T., Fite, B., Holalkere, V., O’Connor, J., and DiBene, T., “Concept Technologies for High Density Intel Itanium Processor Family Servers,” Intel Developer Forum, San Jose, CA, February 26 – March 1, 2001.
- Friedrich, R., “Towards Planetary Scale Computing: Technical Challenges for Next Generation Internet Computing,” Proceedings of THERMES ’02, 2002, pp. 3-4.

