
Introduction
Artificial intelligence (AI) has emerged as a powerful tool empowering scientists and engineers to interact with computers in innovative ways, thereby revolutionizing numerous fields. By leveraging AI, we can collaborate with machines to solve complex problems, gain valuable insights, and achieve significant advancements across diverse domains. One significant application of AI technology is deep learning-based computer vision for image processing. Computer vision’s primary objective is to enable machines to interpret and comprehend visual data. To describe a scene effectively, the traditional computer vision approach extracts informative patches from digital images through algorithms, such as threshold and edge detection. Deep learning, on the other hand, has emerged as a powerful paradigm in computer vision, revolutionizing how machines process visual information. Deep learning models, particularly convolutional neural networks (CNNs), autonomously learn salient features directly from images. Instead of relying on explicit programming and hand-engineered rules, CNNs are trained on vast amounts of labeled data to automatically discover relevant patterns and structures within images. The advancements have led to great leaps in performance for visual tasks such as image segmentation, classification, object detection and tracking, and restoration. These capabilities have become accessible to the public over the past decade. The ability of machines to accurately analyze and comprehend visual information has the potential to transform our daily lives, advance scientific understanding, and revolutionize various real-life applications, as illustrated in Figure 1.
Firstly, deep learning-based computer vision seamlessly integrates into various scientific research fields in Figure 2. One of the main challenges for scientists and engineers has been the capability to interpret scientific data and extract meaningful features from their experiments. The ability of machines to differentiate, harvest, and infer information from images opens new research avenues for researchers to study what has been deemed impossible before. For instance, in the biomedical and healthcare sector, computer vision models are now helping medical physicians make complex diagnostics spanning dermatology, radiology, ophthalmology, and pathology by offering second opinions and detecting anomalies within medical images.
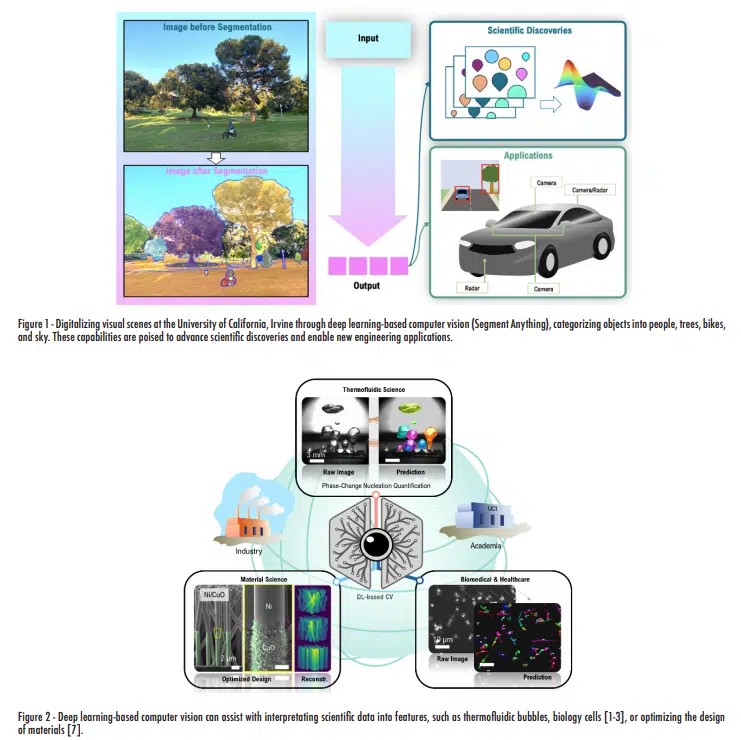
The thermofluidic science community can also tackle century-old problems using modern techniques, such as deep learning-assisted computer vision [1-3]. While phase change processes can create phase boundaries in the forms of bubbles and droplets, the access to these feature statistics can aid researchers in revisiting and building mechanistic models after high-speed videography. The training nature of deep learning-based computer vision models expands the usage applicability to a broad range of other visualization data, such as videography with low resolutions, fluorescence microscopy, and even infrared (IR) imaging. The ability to extract and record physically meaningful features from visual scenes has tremendous implications for real-time monitoring and dynamic analysis of complex behaviors [2, 3], screening and anomaly detection [4-5], and the prediction and forecasting of certain events, such as boiling crisis or dryout [1, 6]. The collaborative information, along with optimization models, can be used to inversely design cooling structures, such as fins, pillar, or channels, for better performance even with a minimum number of experiments [7]. The evidence is clear that computer vision offers tremendous advantages for researchers across various fields. The extent to which such technologies will translate into positive impacts on society depends on how actively they are adopted and explored in various scientific fields.
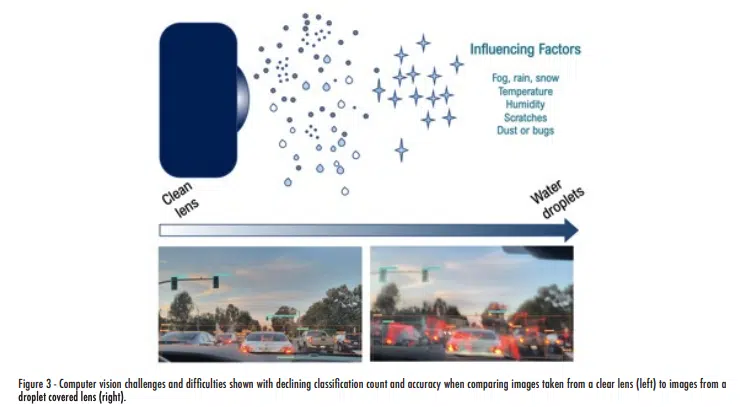
In addition to scientific research, various successes have been achieved in employing computer vision for real-life applications, such as in autonomous robots or vehicles. [9]. Autonomous robots include delivery drones for fast package transport or search robots for locating people during disaster or collecting information at other planets. Once again, visual information from various sensors plays a critical role in assisting with applications. In this process, it is imperative to collect high-quality visual information. However, the process faces numerous challenges arising from external factors, such as fog, rain, dust, and bugs, and internal factors, such as temperature and thermal cycling, as demonstrated in Figure 3. For instance, condensed droplets or frost on the camera lens obstruct the physical view during image collection. Moreover, the distribution of rain or fog droplets affects the quality of visual data captured by sensors like LiDAR due to scattering effects on transmission wavelengths. Therefore, it becomes crucial to understand various influencing factors and their impact on the visual information and performances.
Addressing concerns about the impact of various influencing factors on optical measurements can involve either hardware or software solutions. Mechanical or materials scientists have developed hardware solutions to be incorporated and researched to remove debris and buildup on optical lenses. External camera lenses are coated with hydrophobic materials to prevent condensation and further frosting. Or lenses are installed with cleaners that involve a high-pressure spray system with a small amount of water. There are also research directions involving electrostatic and pulse heating, which can prevent or delay particle attachment or droplet formation on the surface. While hardware solutions have been developed for a long time, software solutions are gaining popularity due to recent developments in deep learning-based computer vision technology. Post-processing through software solutions has led to an exploration of image restoration or reconstruction, a technique used to remove artifacts from a corrupted image to a clean image. The conventional approach to image restoration involves filling in missing or affected regions with information from surrounding pixels. However, this method, known as inpainting, was limited by the available information in the image. When dealing with large-affected areas, the surrounding pixels may not provide sufficient data to restore the missing sections effectively.
Recent advancements in deep learning methods have helped address the issue of insufficient pixel information in image restoration. These methods typically involve the use of encoder-decoder neural networks. Training datasets for these networks consist of pairs of corrupted images and their corresponding ground-truth images. The encoders are responsible for identifying the image features that require restoration, while the decoders work to recover the image quality during training. Consequently, machine learning models such as generative AI or generative adversarial networks (GANs) are now emerging as promising candidates for addressing computer-vision-related limitations [8-12]. GANs have the benefit of generating discrimination between behaviors. GANs aim to emulate human brain characteristics and generate outputs consisting of two sets of convolution layers simultaneously trained with a generator and a discriminator. The generator’s role is to produce authentic-looking images, while the discriminator’s task is to differentiate between real and generated ones. In scenarios where artifacts are present, the generator employs an attentive-recurrent network assigning higher values and weights to focus on corrupt regions during training. Through numerous epochs of training, the recurrent features are emphasized, creating an accurate mask that highlights the region needing restoration. The iterative process continues until the discriminator can no longer distinguish the fake images generated by the generator from real images, thereby signifying the completion of the restoration process.
The GAN’s restoration capability can also improve the capability of object segmentation and classification even with environmental artifacts, in this case, droplets, as shown in Figure 4 [8], which is essential for autonomous robots or vehicles. Here, the images are captured when the droplets are sprayed on the optical camera. The sprayed droplets are segmented and quantified by counting the number of pixels above a threshold of 50, resulting in four levels of increasing artifact severity: 1, 2, 3, and 4. The samples are thereby labeled as 1, 2, 3, and 4 accordingly. For the evaluation, the images are segmented by using computer vision algorithms to count the number of objects of interest (e.g., cars). Subsequently, the restored images after applying GAN are analyzed. Figure 4 showcases the images before and after GAN restoration. The plot (right bottom) indicates that the number of classified objects increases by 30%, and the probability of classification increases by 10% after GANs restoration. These findings confirm the potential of GAN and deep learning-based computer vision models for real-world scenarios, especially in mild weather conditions.
This GANs’ restoration capability can also contribute to data interpretation. Researchers often face challenges in obtaining high-quality data, especially when conducting experiments involving high-speed videography, as is the case in processes like boiling and condensation, which involve rapid nucleation and departure activities. It’s crucial to emphasize that GANs not only excel at eliminating unwanted artifacts and repairing corrupted image segments but also possess the potential to offer intuitive, high-speed screening and analysis capabilities for rapidly evolving and intricate processes through automated object deblurring. Consequently, the integration of such deep learning-based computer vision applications holds the potential for practical improvements in enabling high-quality video analysis or screening, even with non-laboratory-grade cameras.
Despite all the promising aspects of machine learning, it’s important to recognize that deep learning models come with inherent costs. Developing robust models requires the use of extensive datasets and multiple training iterations. For example, in a recent paper focused on scientific discoveries related to bubbles and droplets, a minimum of 2,500 images were used for training and testing the deep learning models [4], even with a ResNet backbone. It’s worth noting that such ResNet backbones are often pre-trained on millions of images from the ImageNet database, enabling the pretrained network to classify images into 1,000 object categories. This emphasizes the importance of utilizing pretrained networks that can cover diverse domains, substantially reducing the computational demands of model training.
Acknowledgements
We want to acknowledge the support and funding provided by the Office of Naval Research (ONR) and the National Science Foundation (NSF). We would like to extend our gratitude to Annie Dinh & Liu Laboratory, Chuanning Zhao, Ruey-Hwa Cheng, and Miri Chen for their valuable contributions to the image data used in this study.
References
[1] Y. Suh, R. Bostanabad, and Y. Won. “Deep learning predicts boiling heat transfer.” Scientific reports, 11.1, 1-10, 2021.
[2] Y. Suh, et al. “A deep learning perspective on dropwise condensation.” Advanced Science, 8.22, 2101794, 2021.
[3] J. Lee, Y. Suh, M. Kaciej, P. Simadiris, M. T. Barako, and Y. Won. “Computer vision-assisted investigation of boiling heat transfer on segmented nanowires with vertical wettability.” Nanoscale, 14.36, 13078-13089, 2022.
[4] K-H. Yu, A.L. Beam, and I. S. Kohane. “Artificial intelligence in healthcare.” Nature biomedical engineering, 2.10, 719-731, 2018.
[5] C. Zhao, J. T. Eweis-Labolle, R. Bostanabad, and Y. Won, “Inverse Engineering of Spatially Varying Micropillars for Heterogenous Heat Map,” presented at Third Conference on Micro Flow and Interfacial Phenomena (µFIP), June 2023, Evanston, IL, USA.
[6] X. Dong, et al. “Microscopic image deblurring by a generative adversarial network for 2d nanomaterials: implications for waferscale semiconductor characterization.” ACS Applied Nano Materials, 5.9, 12855-12864, 2022.
[7] A. Rokoni, L. Zhang, T. Soori, H. Hu, T. Wu, and Y. Sun. “Learning new physical descriptors from reduced-order analysis of bubble dynamics in boiling heat transfer.” International J. Heat and Mass Transfer, 186, 122501, 2022.
[8] Y. Suh, P. Simadiris, S.H. Chang, and Y. Won, “In micro Flow and Interfacial Phenomena,” presented at MicroFIP, Irvine, 2022.
[9] D. Floreano and R. J. Wood. “Science, technology and the future of small autonomous drones.” Nature, 521, 460-466, 2015.
[10]Z. Xiong, W. Li, Q. Han, and Z. Cai. “Privacy-Preserving Auto-Driving: A GAN-Based Approach to Protect Vehicular Camera Data,” presented at 2019 IEEE International Conference on Data Mining (ICDM), Beijing, China 668-677, 2019.
[11] N. V. Quach, et al. “Machine Learning Enables Autonomous Vehicles under Extreme Environmental Conditions,” presented at 2022 ASME interpack, Garden Grove, CA, USA, 2022.
[12]J. Zhang, H. Chen, and Z. Wang. “Droplet Image Reconstruction Based on Generative Adversarial Network.” J. Phys. Conf. Ser., 2216, 012096, 2022.
[13]R. Singh, R. Garg, N. S. Patel, and M. W. Braun. “Generative Adversarial Networks for Synthetic Defect Generation in Assembly and Test Manufacturing.” Asmc Proc, 9185242, 2020.
[14]Y. Suh, et al. “VISION-iT: Deep Nuclei Tracking Framework for Digitalizing Bubbles and Droplets.” Available at SSRN 4491956, 2023.
[15] S. Chang, et al. “BubbleMask: Autonomous visualization of digital flow bubbles for predicting critical heat flux.” International Journal of Heat and Mass Transfer, 217, 2023.


